이름 붙이기 전에 먼저 느껴진다. 인디고에서 바이올렛으로 가는 그라데이션, 흰 배경의 Inter, 히어로 다음에 이모지가 하나씩 박힌 카드 세 개, 모든 것에 같은 보더-라디우스, 모든 것 아래 같은 부드러운 그림자, 그리고 *미래를 만드세요*라고 약속하는 헤드라인. 모델이 만든 페이지의 룩이고, 이제 팀들은 자기 AI 출력이 AI처럼 보이지 않게 하려고 실제 시간과 토큰을 태운다. 흔한 설명은, 그 룩을 벗어나려면 취향이 필요하고 그건 모델에 없으며 적어둘 수 없는 것이라는 말이다.
절반만 맞다고 본다. 모델에 취향이 없는 건 사실이다. 그러나 벗어나야 할 대상은 형언 불가능하지 않다. 'AI 룩'은 *분포적 산물*이다. 개별적으로는 평범하지만 학습 데이터의 최빈값에 있기 때문에 집합적으로 과대표집된 선택들의 집합. 인디고가 기본값인 이유는 수년 전 Tailwind 예제가 모든 버튼을 그 색으로 기본 설정했고, 모델이 '모던함'과 보라색의 상관을 학습했기 때문이다. 유한하고 반복되는 것은 무엇이든 적어두고, 가중치를 매기고, 측정할 수 있다.
룩을 열거하다
우리는 반복되는 신호를 여덟 패밀리, 27개 흔적(tell)으로 정리했다. 색·타이포·레이아웃·여백·표면·모션·카피, 그리고 현장에서 얻은 AI 자기참조(아래 참조). 각 흔적은 무엇을 검출할지(작동적 정의), 모델이 왜 그것을 기본값으로 삼는지(근거), 그리고 디자이너라면 어떻게 고칠지(수정법)로 정의된다. 가장 시끄러운 것은 뻔한 것들, 인디고 팔레트와 Inter 기본값, 이지만, 가장 *결정적인* 것은 조용한 것들이다. 디자인된 호버·포커스·액티브 상태가 없는 상호작용 요소, 그리고 사라진 포커스 링. 애초에 고려되지 않은 마이크로상태와 접근성의 잔여물이다.
투명한 검출기가 HTML 파일 하나를 읽어, 원시 CSS와 Tailwind 유틸리티 클래스를 모두 해석하고, Tell Score를 0에서 100으로 보고한다. 발화한 흔적들의 가중 비율이다. 낮을수록 좋다. 0은 '의도되어 보임', 높음은 '학습셋의 중앙값'으로 읽힌다. 학습된 모델도, 불투명한 숫자도 없다. 모든 점수는 이름 붙은 흔적과 인용된 증거로 추적된다. 각 흔적에는 기억하기 쉬운 별명도 붙어 있어 분류체계를 인용하기 좋다. 무엇에든 'AI'라며 스파클 아이콘을 박는 반사를 *The Sparkle Tax*, 그대로 나간 placeholder 카피를 *Lorem Shipsum*, 카드 안에 카드를 *Box-in-a-Box*로 부른다.
같은 페이지, 흔적을 제거하다
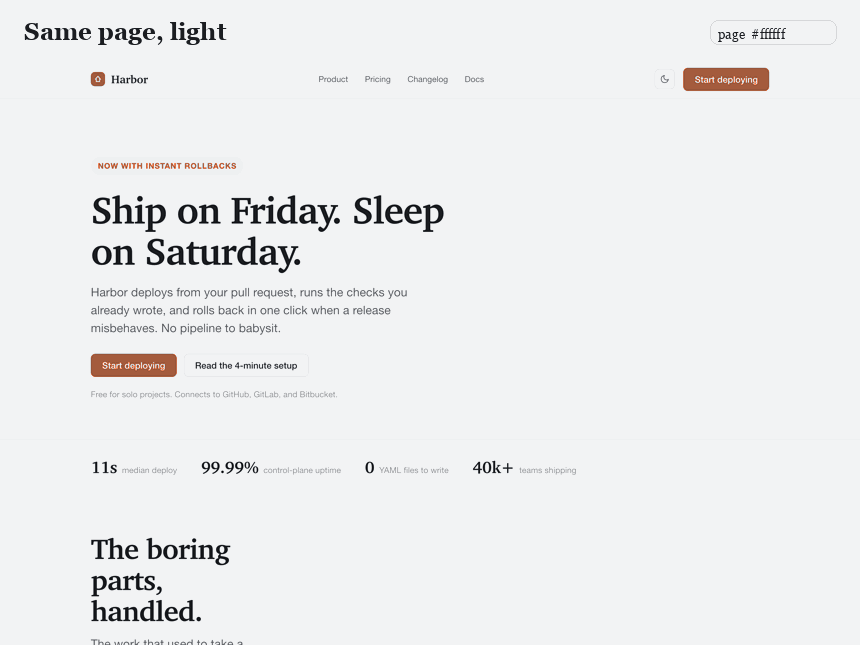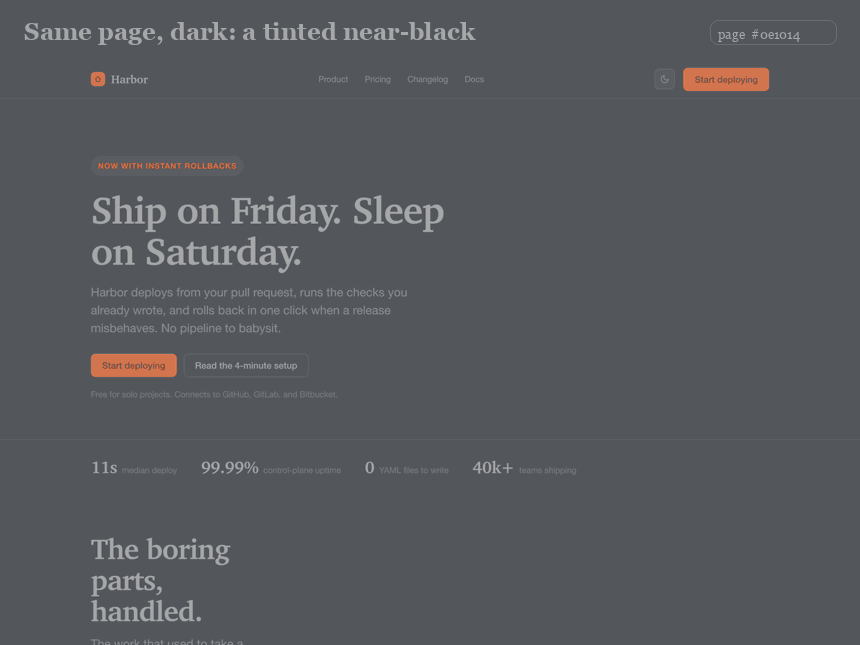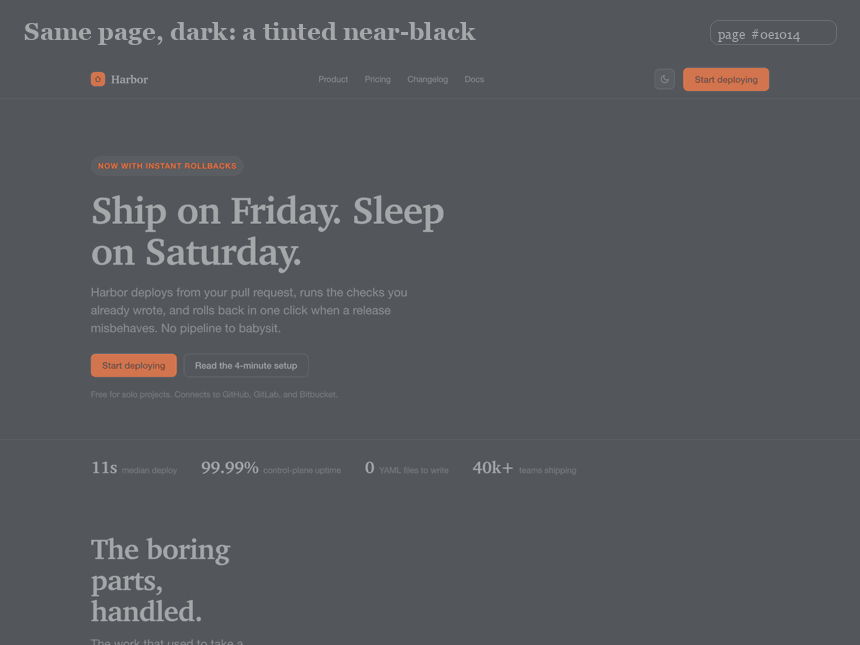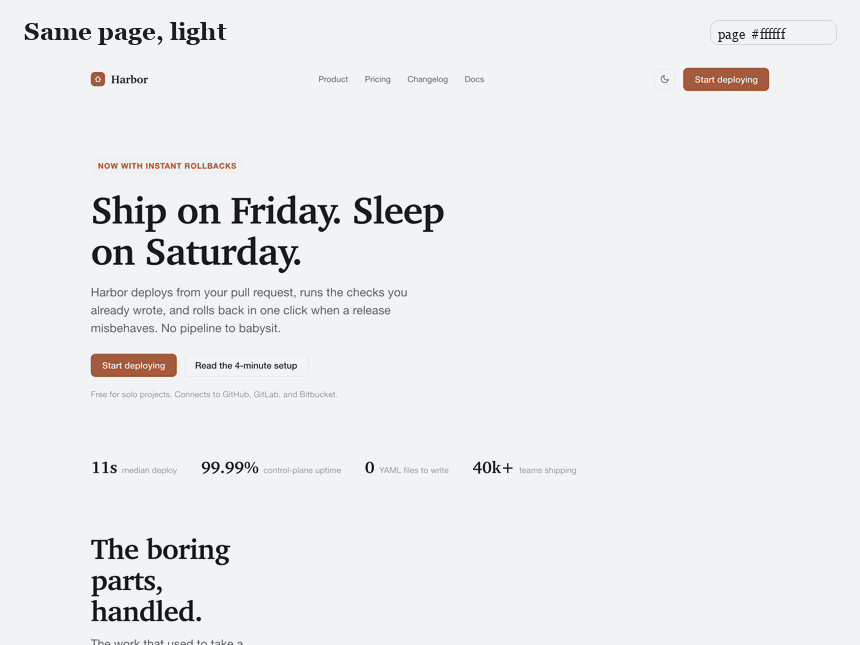
핵심 결과는 의도적으로 교란-통제되었다. 랜딩 페이지 하나를 가져와 *흔적이 되는 속성만* 바꾸도록 리팩터한다. 폰트, 색 시스템, 정렬과 그리드, 라디우스 위계, 입체감과 헤어라인, 모션과 마이크로상태, 그리고 문구. 같은 제품, 같은 네 섹션, 같은 정보. 그 외엔 아무것도 움직이지 않는다. Tell Score는 77(F등급, 교과서적 슬롭)에서 0(A등급)으로 떨어진다. 변화는 콘텐츠가 아니라 디자인이다.
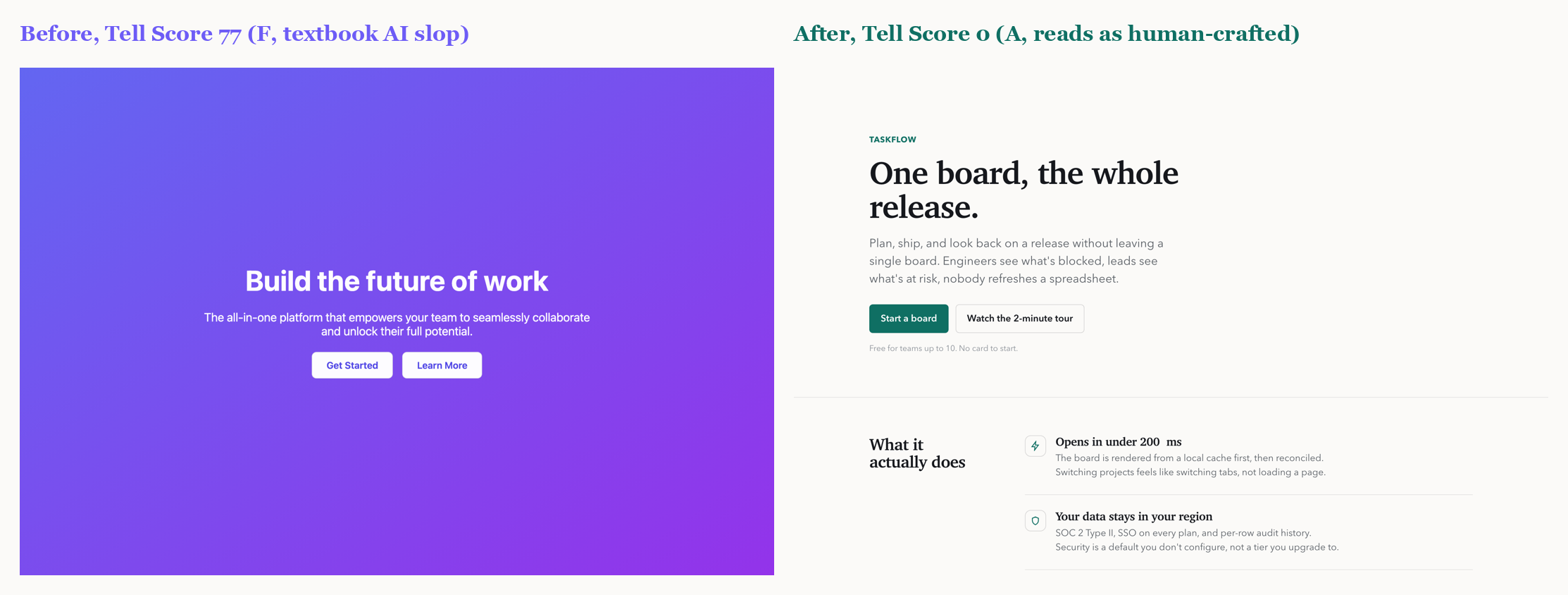
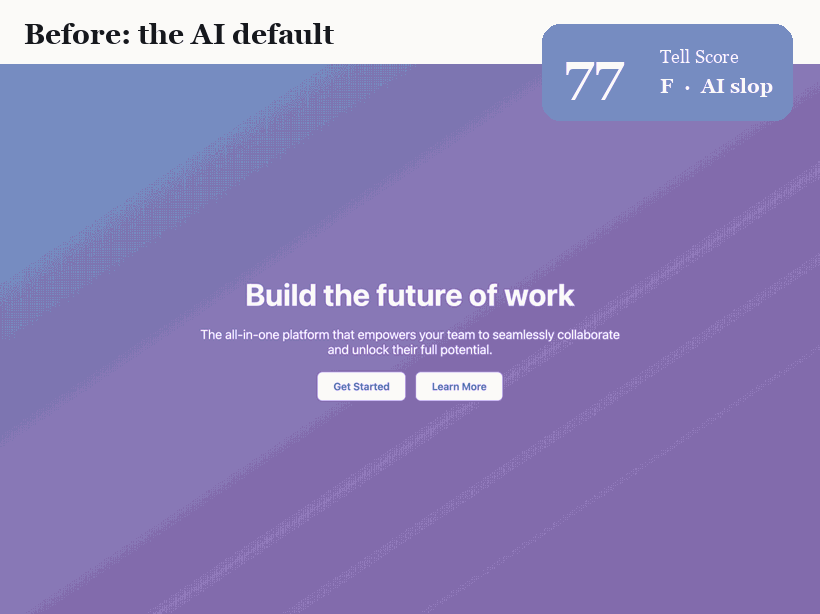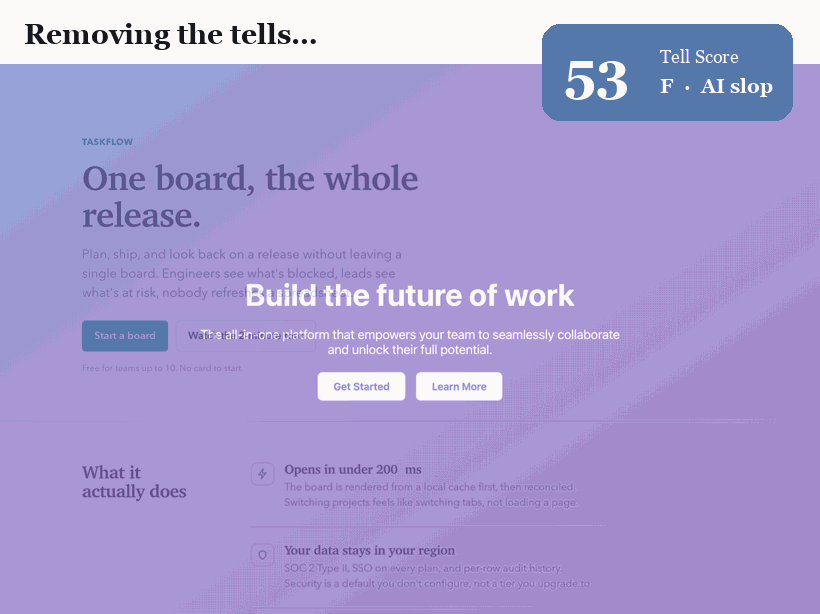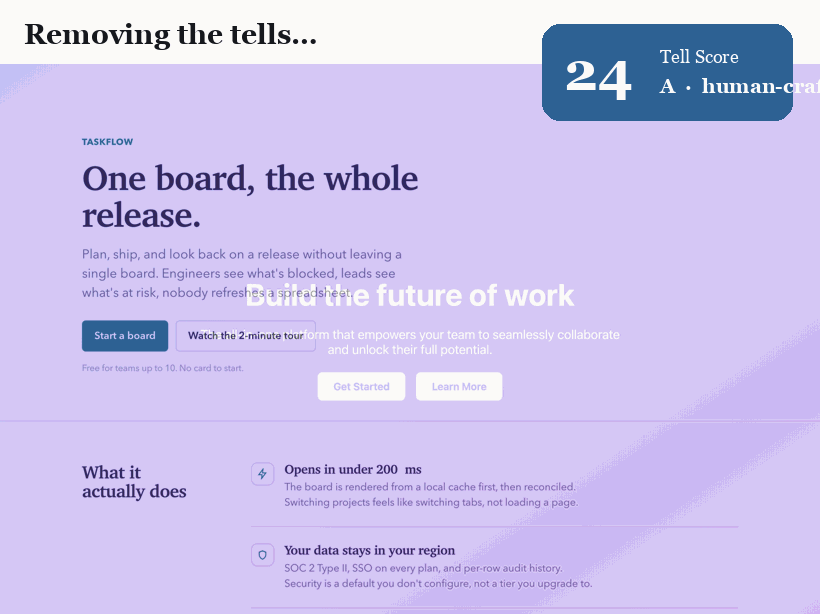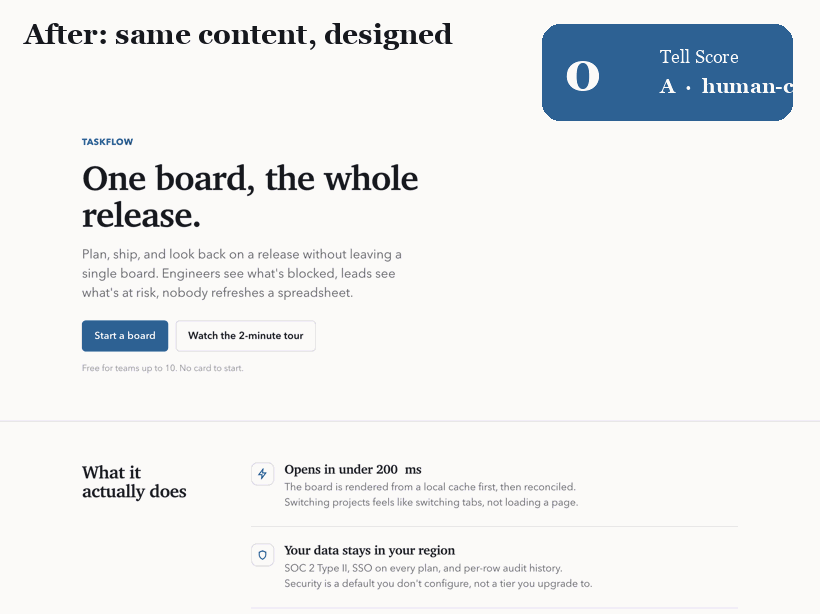
6개 페이지 코퍼스에서 검출기는 AI-기본형(평균 60)과 디자인된 페이지(평균 0)를 겹침 없이 분리한다. 무엇을 보여주는지는 정직하게 말한다. 디자인된 페이지가 0인 것은 흔적이 없도록 *작성했기 때문*이다. 이는 수정법이 점수를 0으로 만들기에 충분함을 보여줄 뿐, 야생의 실제 사이트가 0이라는 주장은 아니다. 짐을 지는 결과는 교란-통제 리팩터와 깨끗한 분리다.
실제 사이트 202개로 검증
정당한 반론: 검출기가 그냥 모든 걸 AI로 모는 것 아닌가? 그래서 디자인 주도의 사람이 만든 사이트 202개(Stripe·Linear·토스·Apple·Vercel·Figma·Notion 등)를 헤드리스 크롬으로 렌더링해 computed style을 읽고, 실제 디자인이 어디에 있는지 학습했다. 그 데이터로 재보정하니 202개 사이트는 중앙값 0점, AI 기본형은 35~59점으로 멀찍이 떨어진다. 이 도구는 우리가 만든 fixture가 아니라 실제 데이터에서 기계-기본값과 사람이 만든 것을 구분한다.
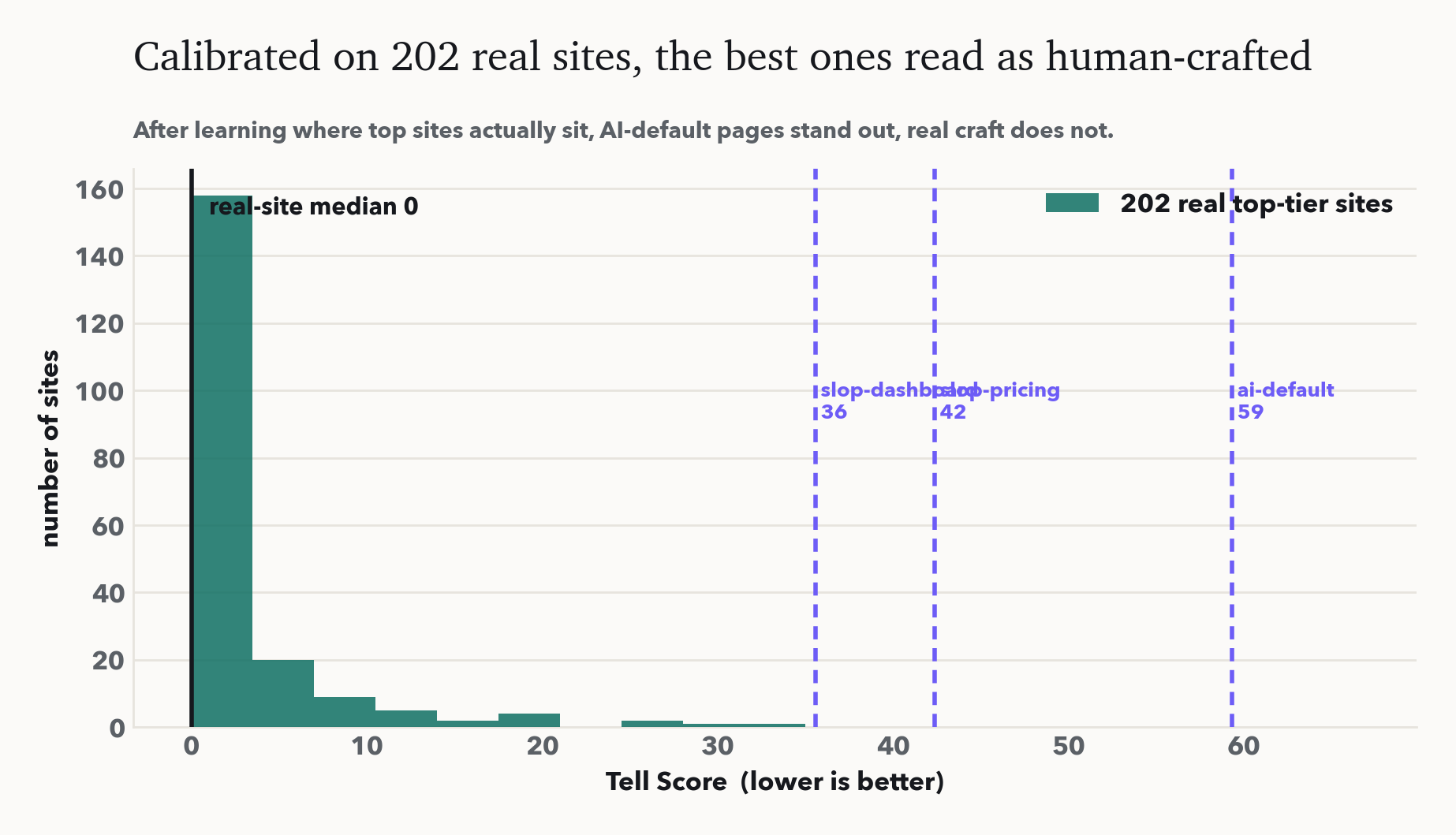
데이터는 통념도 바로잡는다. 브랜드 보라는 tell이 아니다. Stripe는 보라 123개를 칠하고도 0점인데, 그 옆에 커스텀 폰트·광학 트래킹·radius 계층이 있기 때문이다. Inter도 tell이 아니다. top 사이트의 4분의 1이 쓰며 Linear도 실제 타입 시스템과 함께 쓴다. 그래서 우리는 보상 craft가 화장적 기본값을 상쇄하는 craft-크레딧 모델로 채점한다. 단일 신호는 tell이 아니다. AI 룩은 아무것도 결정하지 않은 채 쌓인 기본값의 묶음이다. 같은 검출기가 이제 코드 문자열뿐 아니라 라이브 URL도 감사한다.
'하지 마'에서 '이렇게 해'로: 스펙 카탈로그
검출기는 늘 *하지 말아야 할* 것만 말한다. 실제로 만들려는 사람의 질문은 긍정형이다. 그럼 어떤 값을 쓰라는 거지? 그래서 같은 증거에서 답을 읽었다. 그 사이트들 중 199개를 다시 렌더링하되, 이번에는 컴포넌트별로 실제 적용된 CSS를, 라이트·다크 양쪽에서 prefers-color-scheme마다 한 번씩, 사이트당 두 번 기록했다. 결과는 하우스 스타일이 아니라 측정된 레퍼런스다.
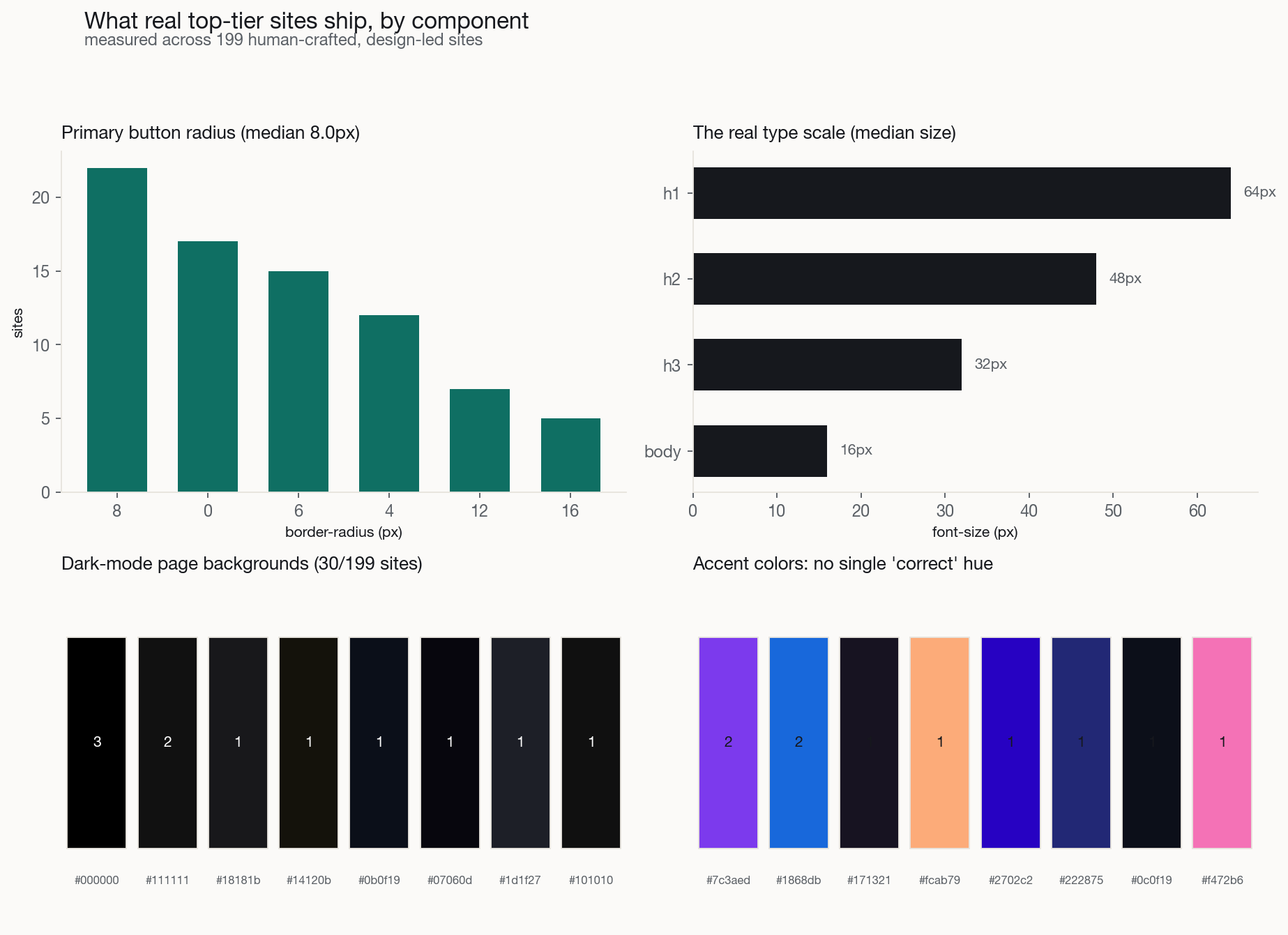
몇 가지 숫자. 프라이머리 버튼의 모서리 라디우스는 하나의 값으로 수렴하지 않는다. 8~12px의 부드러운 둥근형과 완전한 알약형으로 갈리고, 각진 모서리는 의도적 소수이며, 버튼에 그림자를 다는 경우는 13%뿐이다. 실제 타입 스케일은 16px 본문 위로 헤딩이 64 / 48 / 32px 부근에 자리하고, 헤드라인은 좁은 행간에 음수 자간이 잦다. 콘텐츠 컨테이너는 1200px 중앙값. 간격은 4/8px 그리드를 따르되 약 70%만, 생성기가 가정하는 종교적 준수가 아니다. 그리고 다크 모드에는 문법이 있다. 페이지 배경은 거의 순수 검정이 아니라 *색조가 들어간* 근사-검정이고, 띄운 표면은 헤어라인 보더가 아니라 한 단계 밝은 색이며, 텍스트는 순백이 아닌 오프-화이트다. 컴포넌트별 전체 표와 사이트별 부록은 저장소에 reference/COMPONENT-SPECS.md로 함께 공개하며, 하네스는 이제 이 목표값을 담아 양면적으로 안내한다.
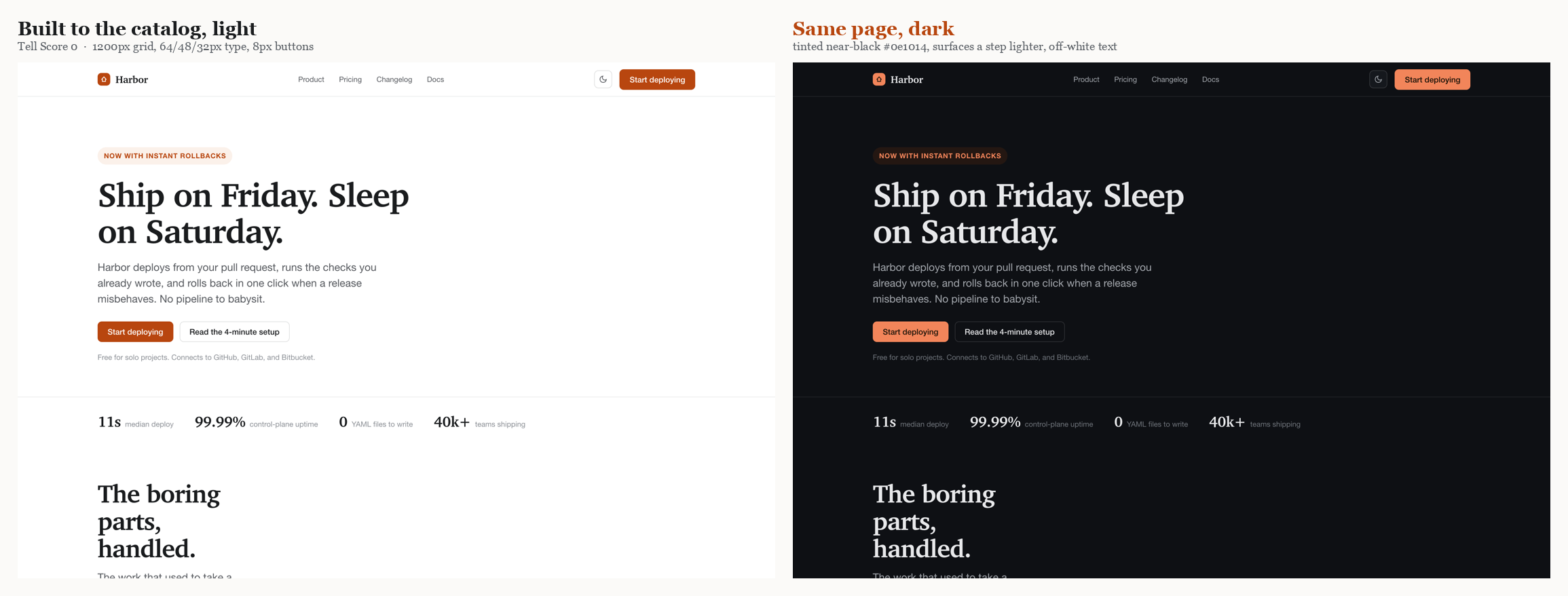
목표값이 설명만이 아니라 실제로 만들 수 있음을 증명하려, 그 중앙값들로 랜딩 페이지 하나를 직접 조립했다. 1200px 컨테이너, 64/48/32px 세리프 타입 스케일, 모든 마이크로상태를 갖춘 8px 버튼, 기본 인디고 대신 고유한 앰버 액센트, 그리고 측정된 문법을 따르는 다크 모드. 자족적인 파일 하나이며, 라이트·다크 양쪽에서 Tell Score 0을 받는다.
한국어 타입은 다르다, 두 가지가 그리고 세 번째는 아니다
위 카탈로그는 대부분 서구권이고, 한글은 라틴과 다르게 짜인다. 그래서 같은 추출을 한국 디자인 주도 사이트 48개(토스, 카카오, 당근, 무신사, 29CM, 오늘의집, 배민, 업비트 등)에 돌려 비교했다. 정직한 결과는 진짜 차이와 통념을 가른다.
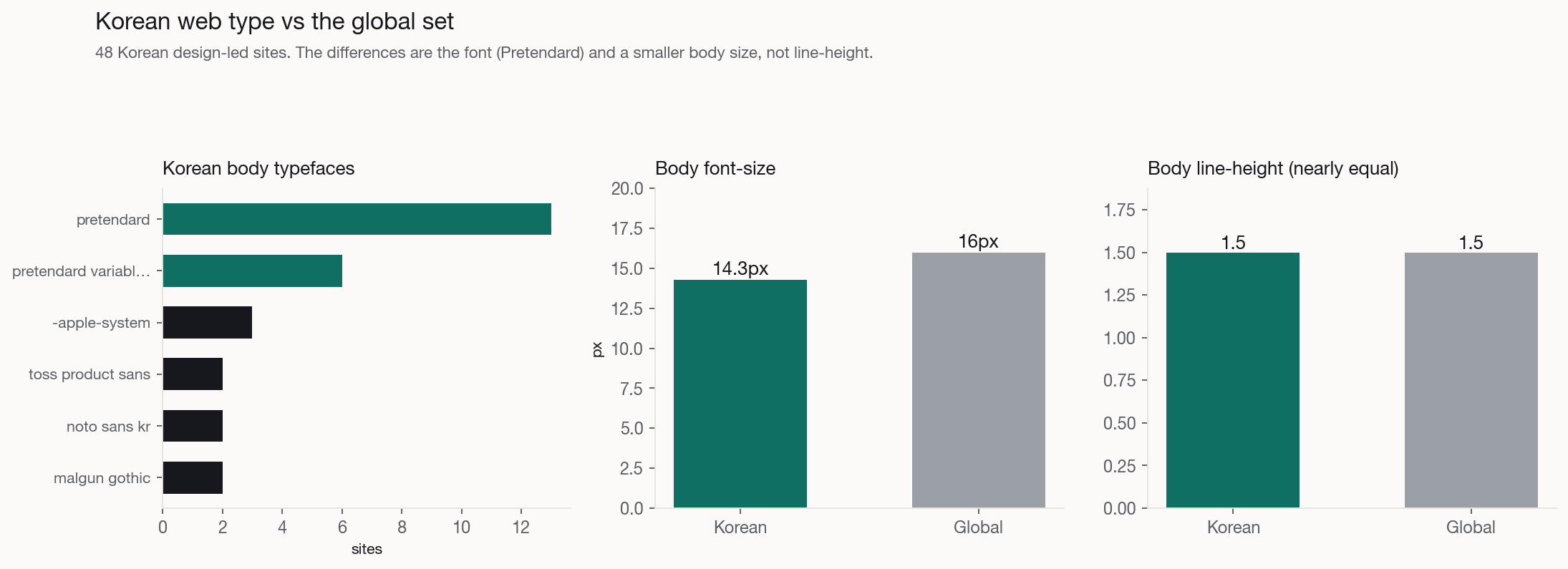
진짜로 달라지는 건 둘이다. 폰트: Pretendard는 한국 웹의 Inter다. 무료에 힌팅이 잘 된 기본값으로, 이 사이트들의 44%가 본문 폰트로, 69%가 어떤 한글 산세리프를 쓴다. 그래서 타입 흔적은 그대로 번역된다. 스케일 없이 맨 Pretendard를 쓰는 건 맨 Inter만큼 기계-기본값으로 읽히고, 고유한 수는 커미션 폰트(토스 프로덕트 산스, 빗썸 트레이딩 산스, 지마켓 산스, 원티드 산스)다. 그리고 본문 크기: 한국어는 더 작게 짠다. 글로벌 16px 대비 14px 중앙값인데, 한글이 글리프당 잉크가 많고 한국 제품 문화가 더 밀도 높기 때문이다. 통념인 차이는 행간이다. 한글은 훨씬 넓은 행간이 필요하다고들 하지만, 측정된 중앙값은 양쪽 다 약 1.5다. Pretendard가 이미 넉넉한 행간을 기본으로 싣기 때문이다. 정직한 단서 하나: 한국 h1 중앙값은 이중분포다. 디자인 주도 제품 사이트는 서구처럼 56~90px 히어로를 쓰고, 포털·커머스는 배너 중심으로 작거나 없는 디스플레이 헤드라인을 둔다. 즉 낮은 집계는 헤드라인 개념의 차이가 아니라 밀도 문화다.
두 팀이 이미 금지한 것
가장 날카로운 확증은 반대 방향에서 왔다. 우리는 이 분류체계를 전혀 모른 채 자체 내부 디자인 원칙 문서, 사실상 *AI 같은 룩을 피하라*를 이미 써둔 실제 상용 코드베이스 두 곳에 접근할 수 있었다. 둘 다 정리 작업을 인스턴스 수까지 세어 기록했다. 한 팀은 12px 미만 라벨 약 600건을 12px 바닥으로 올렸고, 다른 팀은 제거할 Sparkles 아이콘을 전부 열거했다. 둘 다 비공개 상용 제품이라, 다크 모드 미디어 도구와 생산성 비서로 익명 처리한다.
두 가지가 중요하다. 첫째, 그들은 검출기가 이미 가진 흔적을 독립적으로 지목했다. 인디고 기본값, 파랑-보라 그라데이션(말 그대로 "AI 풍 그라데이션"으로 금지), 이모지 아이콘, 일반 폰트, 시스템 말투의 막연한 카피. 자기 제품이 생성형처럼 보이지 않게 하려고만 쓴 실무자들이 같은 목록에 도달했다. 패밀리가 우리 프레이밍의 산물이 아니라 실재한다는 가장 강한 증거다.
둘째, 현장이 더 멀리 봤다. 둘 다 분류체계가 다루지 않던 영역, 즉 인터페이스가 스스로 AI임을 광고하는 것을 맨 앞에 두었다. 우리는 이를 새 패밀리 H, AI 자기참조(흔적 3개)와 기존 패밀리의 3개로 더했다:
- AI 클리셰 아이콘, 어떤 'AI' 기능에든 박는 Sparkles / Wand / Bot / Brain / Cpu 세트. - 기능을 'AI'로 라벨링하거나 모델명을 노출, "AI-powered", "AI 분석", UI에 드러난 GPT-4나 Claude. 기능은 하는 일로 부르고, 모델은 설정에서만. - 생성, 미리보기, 그다음 삽입, 비서 패널 의식. 결과를 콘텐츠에 바로 적용하고 되돌리기를 맡겨라. - 다색 pill 배지 인플레이션, 저마다 다른 밝은 색의 상태 pill 한 줄. - 가독 이하 마이크로 타이포, 흩뿌린 9~11px 라벨; 12px 바닥을 둬라. - 이중 박스, 카드 안의 카드; 외곽 카드 하나에 평면 구분 리스트.
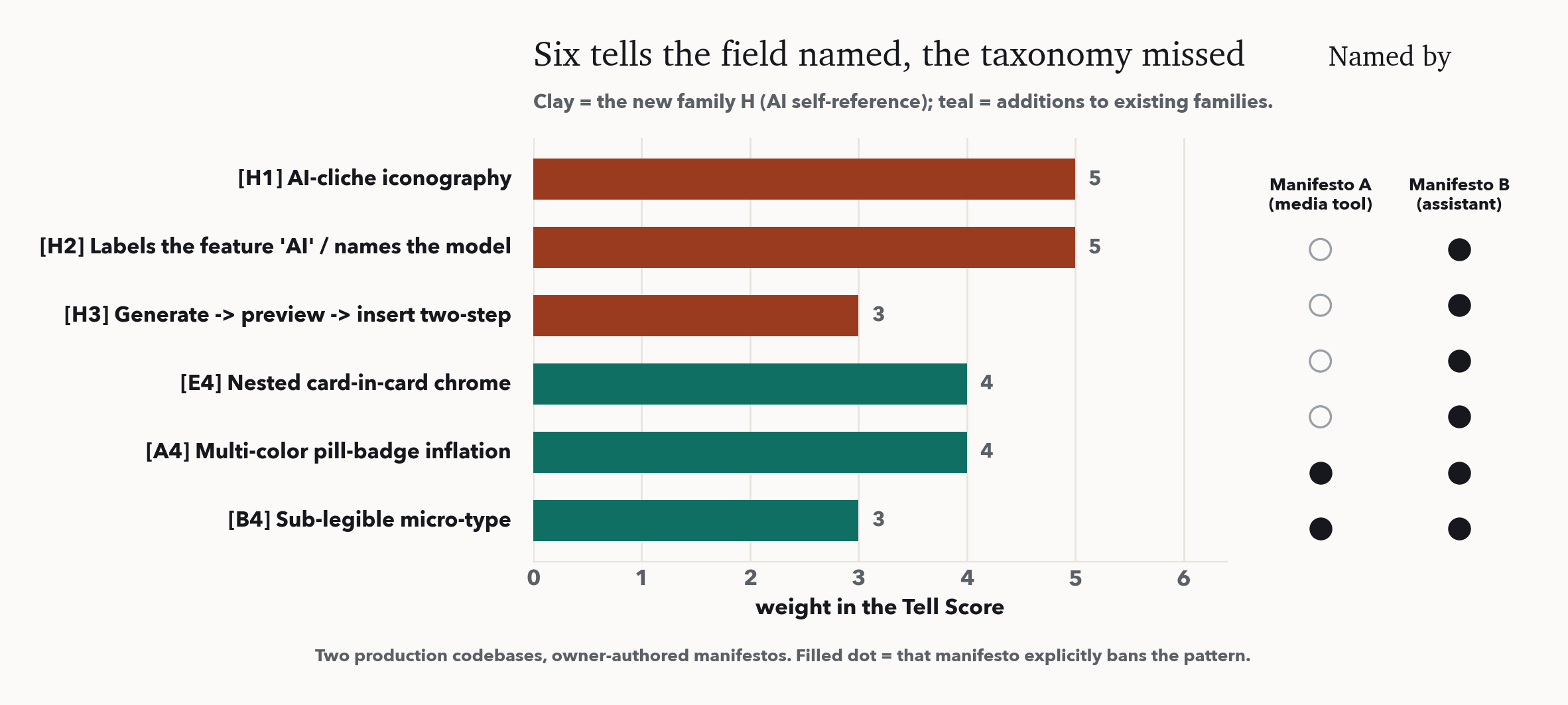
이 여섯으로 분류체계는 27개 흔적이 된다. 에이전트가 방금 쓴 마크업에 돌리는 코드 검출기에서 아이콘 임포트와 라벨 텍스트가 보일 때 발화한다. 라이브 computed-style 감사는 아직 이를 보지 못하며, 이는 결과가 아니라 경계로 명시한다.
판결이 아니라 하네스
분류체계는 하나의 소스에서 세 가지 도구로 제공된다. 종료 코드로 CI를 막는 커맨드라인 린터. 코딩 에이전트가 방금 만든 UI를 당신에게 보여주기 *전에* 스스로 감사하고, 구체적 수정법을 받아 반복하게 하는 MCP 서버. 그리고 각 검출된 흔적을 예방 지시문으로 바꿔 시스템 프롬프트·CLAUDE.md·v0/Lovable 지시 필드에 붙여넣는 드롭인 프롬프트 모듈. 흐름은 생성, 채점, 수정, 재채점이다.
한 줄로 설치
PyPI에 공개돼 있고 Claude Code 플러그인으로도 제공된다. 가장 빠른 길은 플러그인이다. /plugin marketplace add hankimis/ai-design-tells 를 실행한 뒤 /plugin install ai-design-tells@iov-labs 하면 MCP 서버가 등록된다. Cursor나 Claude Desktop 같은 다른 MCP 클라이언트는 uvx 명령을 가리키면 되고, 그냥 pip install ai-design-tells 면 터미널에 ai-design-tells 명령이 생긴다. 어느 방식이든 에이전트가 방금 만든 UI를 보여주기 전에 스스로 감사해, 발화한 각 흔적을 별명·증거·수정법과 함께 돌려주고 Tell Score가 떨어질 때까지 반복한다. 플러그인과 uvx 경로는 서버를 uv로 실행하므로 curl -LsSf https://astral.sh/uv/install.sh | sh (또는 brew install uv)로 한 번만 설치해두면 된다. 일반 pip 경로는 필요 없다.
"AI 같다"는 기계가 만들었다는 뜻이 아니다. 특정한 누군가가 만들지 않았다는 뜻이다. 그라데이션은 못생긴 게 아니라 *주인이 없는* 것이다. 흔적을 제거하는 일은 페이지에 주인을 되돌려 놓는 일이다.
마지막 아이러니가 있고, 그래서 우리는 이 점수를 겸손하게 둔다. 동반 연구 *수렴 압력*은, 집단을 동질화하는 것이 AI 보조가 아니라 모두가 같은 신탁을 참조하는 *루프*임을 발견했다. 널리 채택된 단일 디자인 점수가 바로 그런 신탁이다. 모든 팀이 같은 Tell Score를 같은 수정법으로 최적화하면, 인디고 평균에서의 탈출은 새로운 평균이 된다. 이 하네스의 올바른 쓰임은 우리가 줄곧 주장한 그것이다. *결정의 부재*를 가리키는 검출기, 선택을 하라는 촉구이지, 어떤 선택을 하라는 처방이 아니다. 그것은 당신을 새로운 공유 분포가 아니라 당신 자신의 분포로 보내야 한다. 코드·데이터·그림·하네스는 공개되어 있다.